Diagnóstico de datos
El portal de datos abiertos del contratación Colombia Compra Eficiente es la estrategia del Estado para combatir la corrupción con transparencia. Toda la información de los contratos que celebran entidades públicas o privadas a nombre del Estado debe quedar consignada aquí para que cualquier ciudadano pueda verla y, si detecta alguna irregularidad, actuar.
En este momento, en el sistema hay más de 6 millones de contratos desde 2006 hasta 2018. En Datasketch nos tomamos el trabajo de analizarlos y encontramos varios errores en la manera en la que se almacena la información. La mayoría son errores humanos al momento de cargar la información. Sin embargo, estos errores ocultan información sobre los contratos que los veedores públicos o investigadores utilizan para encontrar irregularidades.
A pesar de contar con una de las mejores coberturas en torno a contratación pública y del grueso de datos disponibles, existen muchos problemas en la calidad de la información. No hay voluntad ni leyes de transparencia que valgan para combatir corrupción si no podemos acceder a información útil para hacer análisis exhaustivos.
La información que no existe
Uno de los problemas principales cuando se analizan datos, sobre todo aquellos que proveniente de múltiples fuentes, es la cantidad de contenidos faltantes. Muchos de los campos más importantes están vacíos o mal diligenciados.
La mayoría de los campos vacíos tiene un XX, lo que es un problema porque el investigador no puede saber ese variable qué representa.
El gráfico muestra el porcentaje de información faltante para las variables seleccionadas.
El problema se agrava cuando vemos que muchas de estas variables dependen de otras. Por ejemplo, si un contrato no tiene una fecha de finalización, tampoco tiene la cuantía final de ejecución del contrato.
Esto además, hace que aparezca más información faltante de la que puede haber, pues por ejemplo el hecho de que no haya datos de ‘cuantías’ se atribuye en parte a que la base de datos cuenta con contratos que no fueron asignados.
No sabemos quiénes son los contratistas del país
El proceso de identificación de contratistas no es tan simple como parece. Incluso cuando se tienen bases de datos consolidadas de gran tamaño, en principio estandarizadas, nos encontramos lo que llamamos el Efecto Britney Spears. Esto quiere decir que cuando las bases de datos se hacen con intervención humana hay múltiples formas de digitar o escribir un mismo dato.
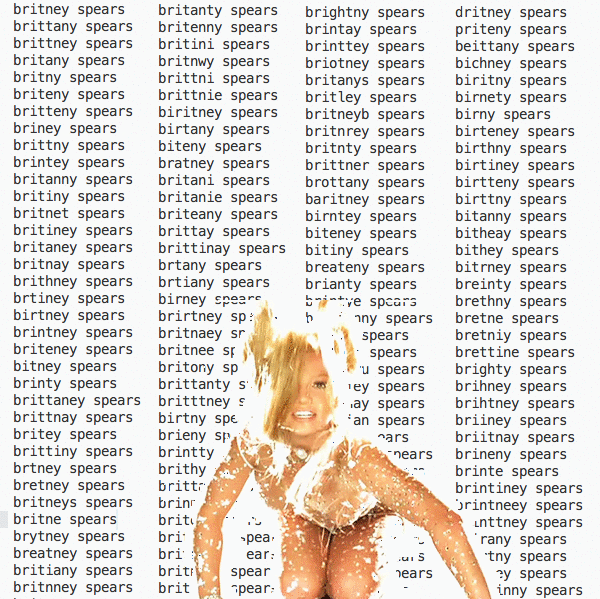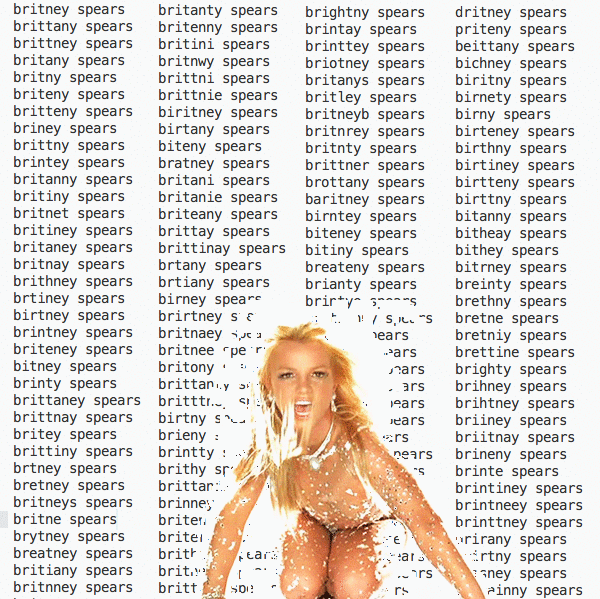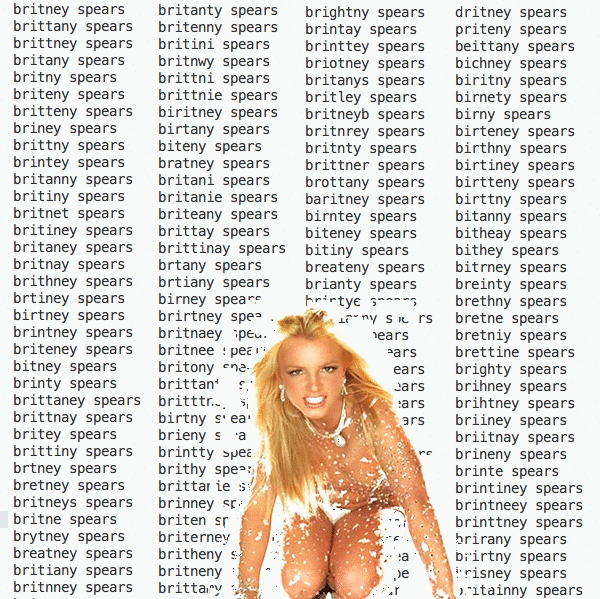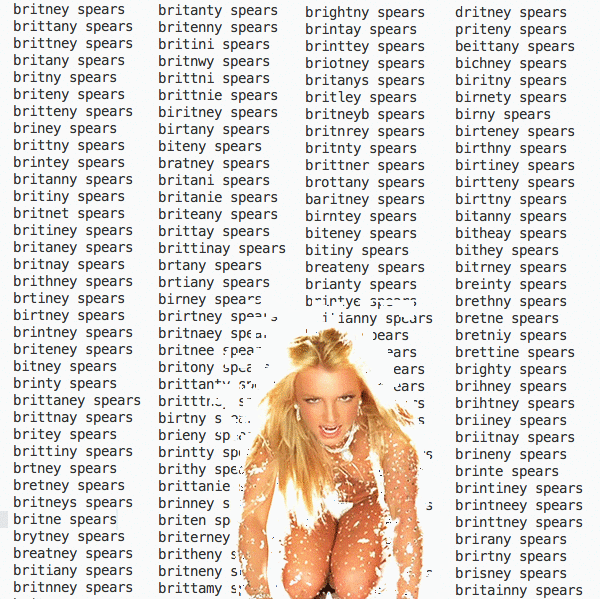
En el caso de los contratos podemos ver diferentes variaciones de nombres, incluso de una misma persona. Entonces ENERIEDH se puede escribir como ENERIEDT, ENERIETH, ENERIHETH, ENERYED. Para el sistema, son personas diferentes. Pero en la realidad, es la misma persona con el nombre escrito de diferentes maneras, debido al mal ingreso de la información en la plataforma. Esto puede hacer parecer que hay múltiples contratistas o múltiples contratos, cuando la realidad es que solo hay uno.
Al ingresar información de contratación pública en el sistema deberíamos ser tan cuidadosos como si estuviéramos haciendo una transferencia bancaria
En los datos de SECOP analizados encontramos retos de limpieza como los siguientes:
- Cédulas con múltiples formatos, por ejemplo con puntos o sin puntos.
- Personas con diferentes nombres y apellidos que tienen el mismo número de cédula.
- La misma persona con su nombre escrito con tildes, sin tildes y cualquier combinación de mayúsculas y minúsculas.
- Nombres de representantes legales que en realidad son nombres de empresas.
- Cédulas o NITs escritos completamente con ceros (00000000) o unos (111111111)
- Cédulas o NITs escritos con los nombres en lugar de los números de identificación de las personas o las empresas.
- Mismos contratistas con diferentes nombres por problemas de digitación.
- Falta de estandarización de siglas de empresas.
- Información escrita en la columna equivocada. Por ejemplo, nombres en campos de cédulas o teléfonos en direcciones.
¿Herramienta para transparencia o para opacidad?
Debido a estos problemas en la base de datos es imposible responderse preguntas tan importantes como cuál es el número de proponentes que tuvo una licitación, una de las banderas rojas a tener en cuenta para detectar la corrupción en la contratación.
Aunque algunas de las ‘banderas rojas’ se pueden atacar utilizando los datos disponibles actualmente en el SECOP I,la falta de información en el formato correcto hace que muchas pasen desapercibidas. Ejemplo de ello son los municipios de ejecución que no tienen código DANE en la base de datos de SECOP.
También ocurren casos en los que definitivamente no hay forma de actuar a partir de los datos porque la información no existe. Por ejemplo, actualmente no se puede verificar cuáles contratos tienen adiciones extemporáneas, si los tiempos de licitación fueron suficientes para todos los proponentes o cómo fue el flujo de facturación de los contratos.
El ejercicio de limpieza y organización de información es una tarea monumental, incluso tan grande como el ejercicio de captura de información y presenta sus propios retos que muchas veces son menospreciados.
Sin embargo, el problema principal en la organización de los datos radica en la falta de responsabilidad sobre la calidad de información. SECOP I funciona como un agregador de datos de múltiples fuentes (más de 6000 entidades), por tanto, cualquier discrepancia en la información debería ser validada y verificada por la propia entidad en lugar de ser publicada automáticamente.
Si encuentras un error en la base de datos debes informar directamente a la entidad contratante, ellos deben notificar a Colombia Compra para corregir la información en la base de datos
Por fortuna con los sistemas transaccionales de compras del Estado (SECOP II y Tienda) muchas de las situaciones descritas en este documento deberían corregirse. Pero mientras este proyecto se hace realidad, estas son las recomendaciones de Datasketch para mejorar la calidad de la información que dejamos para quienes manejen datos de contratación pública en un futuro.
Limpieza
Asegurarse de contar con un software que valide la información digitada por los funcionarios en el momento de carga, incluso con un sistema de validación en marcha. El Estado debe invertir en buenas capacitaciones para que quienes suben la información al sistema lo hagan de forma correcta. Una vez cargada la información, se deben incluir rutinas de limpieza para validar que la información es correcta, asegurándose de que los campos numéricos en efecto son numéricos, de que los de texto son textos o de que las fechas son fechas.
Publicar un diccionario de datos
En cualquier ejercicio de análisis de datos es muy importante contar con descripciones de las variables que se están recogiendo para que todos los usuarios entiendan qué significan. Así, se mantiene una consistencia entre los identificadores de los campos en la base de datos al momento de trabajar con ellos. En el caso de esta investigación, durante las últimas semanas el SECOP agregó nuevas columnas a la base de datos y sin un diccionario claro y actualizado que consultar, por lo que tuvimos muchos problemas técnicos al trabajar con la información de manera automatizada.
Que el NO DEFINIDO sea igual para todos
Nos encontramos con que cada una de las columnas de información como la cédula, el tipo de contrato, los proponentes, etc. cuenta con su propia forma de designar los registros que no tienen información como "No Definido", "No definido", "No definida", "No registra" y otras variantes. Para hacer análisis de información sería conveniente que todos los campos mantengan la misma convención. La recomendación es simplemente dejar la celda vacía. Así, campos que deberían ser numéricos o fechas no se transforman automáticamente en campos de texto.
Cuantías con valor 0
Relacionado con el punto anterior, vemos que en la base de datos de contratos algunos campos que deberían estar vacíos se presentan con el valor cero (0). En los análisis se puede llegar fácilmente a conclusiones erróneas si tomamos contratos que tienen valor cero cuando deberían ser vacíos.
Identificador único
Desafortunadamente, en la base de datos actual no existe un identificador único evidente para cada registro. Existen las columnas del identificador del proceso y del identificador del contrato, pero para estas variables no existen valores únicos. Cada registro en la base de datos efectivamente es un contrato, sin embargo un mismo proceso puede tener múltiples contratos y no hay forma de identificarlos individualmente.
Celdas con múltiples valores
El sistema debería contar con la posibilidad de ingresar información de múltiples valores para un mismo registro. Por ejemplo, la columna de ‘proponentes’ y ‘calificación’ es un campo de texto abierto en el que cada usuario escribe a su antojo. Así, agregar la información para análisis resulta muy difícil de interpretar. En el caso de los municipios de ejecución, este sistema sí funciona ya que cuando hay múltiples valores estos se separan con ";".
Bases de datos complementarias
Es muy importante como ejercicio de veeduría vincular las bases de datos externas que sirvan para completar los análisis. Para el caso particular de los datos de contratación pública dejamos algunos ejemplos:
- Base de datos de entidades del estado con codigo, nombre, total de recursos o presupuesto, ubicación etc.
- Base de datos de declaración de intereses de todos los funcionarios públicos que trabajen directa o indirectamente temas de contratación pública.
- Bases de datos de participación de consorcios y uniones temporales con sus respectivos integrantes y participaciones.